What happened
A new arXiv preprint, MCP-Persona, takes the harder problem seriously. The authors build simulated personal-application environments and benchmark LLM agents on real-world tasks through the Model Context Protocol, instead of grading them on tidy one-shot prompts.
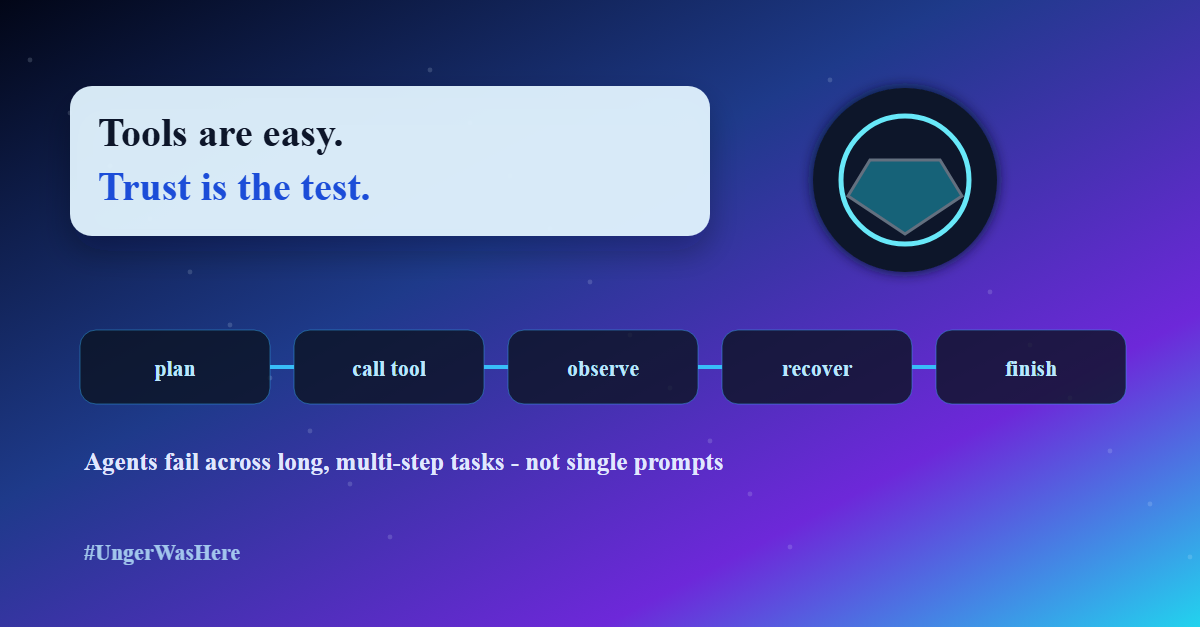
This is the part of the agent story that does not trend but actually matters. An agent connected to your calendar, files, and accounts is only as safe as its behavior across long, messy, multi-step tasks. Benchmarks built on environment simulation are how we find the failure modes before users do.
If you are building agentic systems, the interesting question is no longer can it call the tool. It is can we prove how it behaves before it is wired to anything that matters. I would love to hear how teams here are evaluating agents in realistic environments.
Source
Reported by MCP-Persona: Benchmarking LLM Agents on Real-World Personal Applications via Environment Simulation via arxiv.org, published June 2, 2026.